Our work focuses on applying AI methods to improve the performance of computer and communication systems, e.g., datacenters, hybrid clouds, and networks (AI for systems). We are also interested in optimizing performance of systems running AI inference and training (systems for AI).
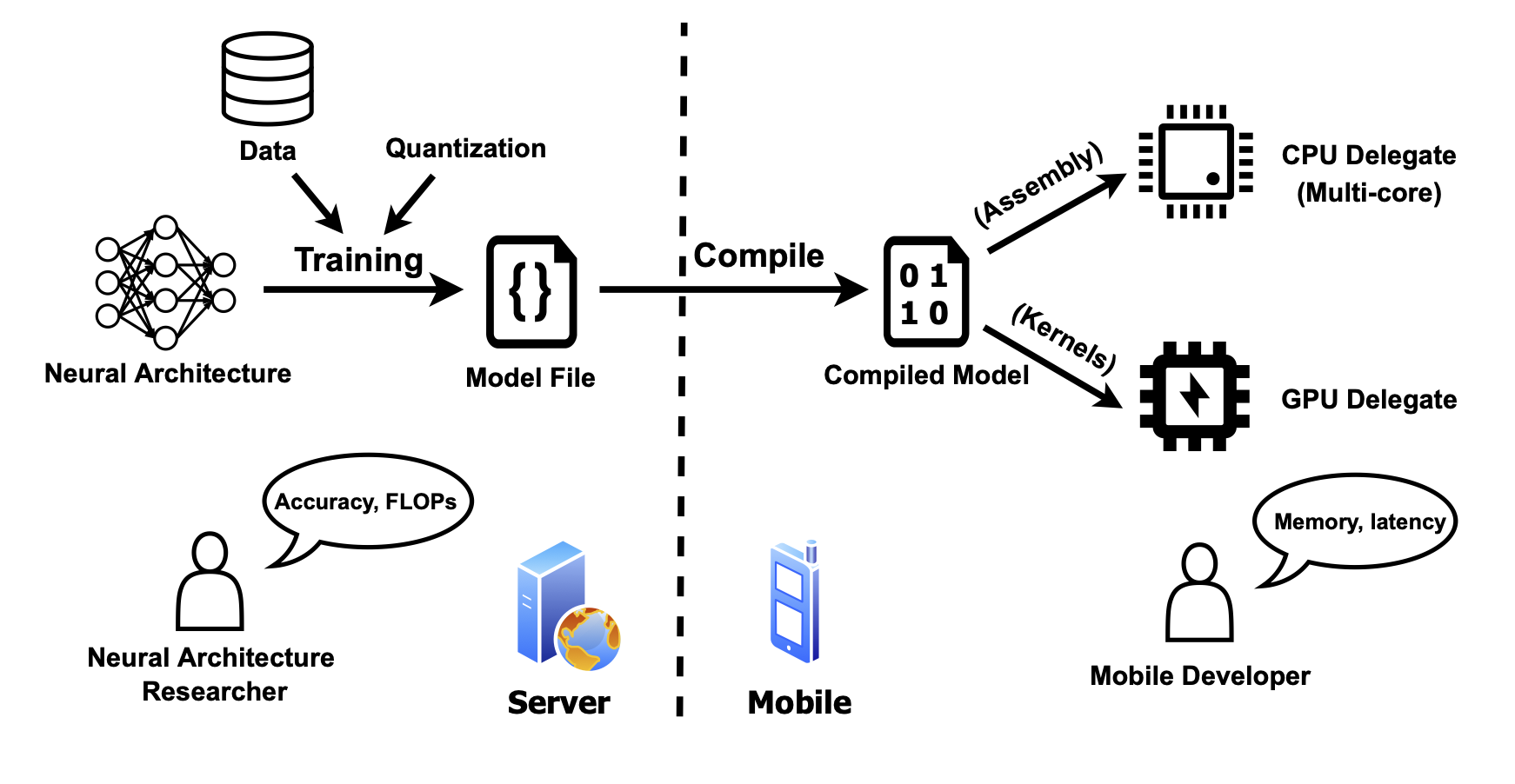
For instance, our recent research focuses on edge and mobile systems with limited computing capabilities. In (Li et al., 2024a), we introduced a dataset of mobile inference latency for 102 real-world CNNs, 69 real-world vision transformers, and 1000 synthetic CNNs across (1) multi-core CPUs and GPUs, (2) floating-point and integer representations, (3) TFLite and PyTorch Mobile frameworks, and (4) six Android and iOS platforms. Based on the dataset, we developed predictive models (Li et al., 2024b) to estimate inference latency (e.g., average errors of 5.4% and 8.0% on CPUs and GPUs for TFLite), demonstrating applicability for practical applications including neural architecture search (NAS) and collaborative inference.
In another effort we focused on training workloads. Machine learning frameworks can easily deploy distributed training jobs over multiple nodes and, within each node, multiple CPU cores or GPUs. The throughput of distributed training is influenced not only by computing resources, but also by networking speeds and coordination mechanisms. Communication bottlenecks and stragglers can cause sublinear scaling - simply adding more nodes does not always result in proportional speedups. In (Li et al., 2022, Li et al., 2020), we proposed both coarse-grained (queuing models) and fine-grained (simulation-based) approaches for throughput prediction. We conducted comprehensive evaluations on over 350 training jobs across up to 96 GPUs, covering (1) synchronous and asynchronous training, (2) centralized (Parameter Server) and decentralized (Ring All-Reduce) infrastructures, and (3) TensorFlow and PyTorch frameworks. The results showed that our approaches can be successfully adapted across a broad range of scenarios, achieving accurate throughput predictions (e.g., average errors of up to 5.8% for Async-SGD on PyTorch).
Another direction is performance and reliability of satellite networks. Inter-satellite links allow network operators to create satellite networks where nodes communicate with each other in addition to ground systems. This increased connectivity enables new operation strategies and new business paradigms, e.g., a provider offering satellite networking to other constellations. We are interested in combining ML techniques with traditional optimization techniques in improving performance and reliability of satellite networks.
We are developing novel AI methods that harness the power of machine learning and multimodal sensor data to drive personalized health and performance outcomes. Our current work focuses on developing simple and interpretable models that result in accurate and efficient predictions.
Specifically (in collaboration with the USC Biomechanics Research Laboratory), we have developed lightweight ML methods to estimate ground reaction force during running from inexpensive inertial sensors; in turn, characterizing the mechanical loading experienced during running can help to identify athletes at risk for stress-related injuries (Song et al., 2024).
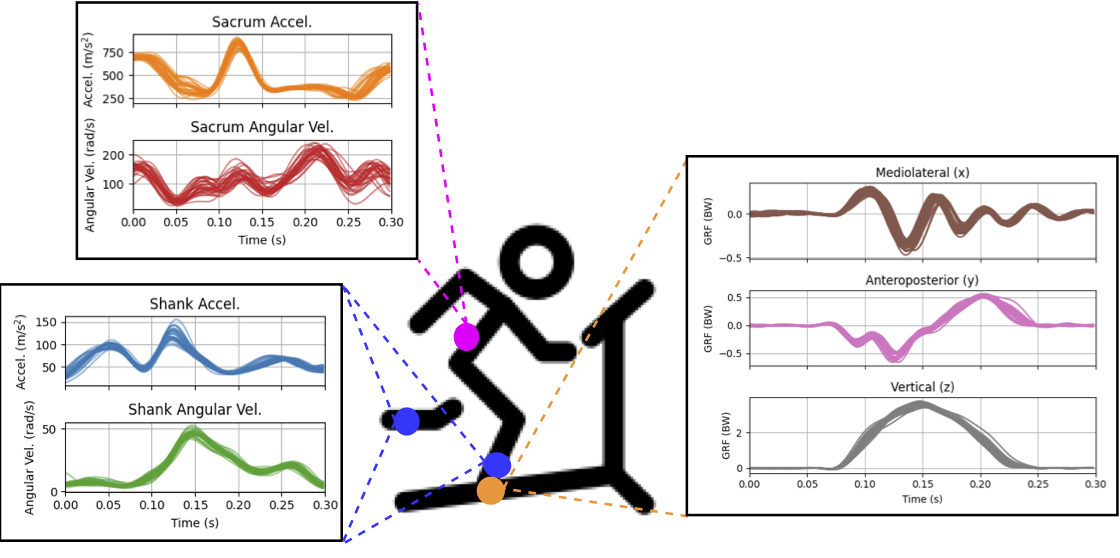
With the growing availability of wearable devices, our future plans include development of AI models that train and fine-tune directly on edge devices, offering real-time feedback, providing continuous monitoring and personalized feedback.
Our recent interest in this area includes work on federated learning (FL) systems that allow multiple users to collaboratively train a shared classification model while preserving data privacy. Although quite useful, FL was shown to be vulnerable to poisoning backdoor attacks. Consequently, our work analyzes the effects of backdoor attacks on federated meta-learning, where users train a model that can be adapted to different sets of output classes using only a few examples. While the ability to adapt could, in principle, make federated learning frameworks more robust to backdoor attacks (hence our motivation to consider federated meta-learning), we find that even one-shot attacks can be quite successful and persist over long periods of time. To address these vulnerabilities, we propose a defense mechanism inspired by matching networks. By removing the decision logic from the model shared with the federation, the success and persistence of backdoor attacks are greatly reduced (Chen et al., 2022).

Another of our interests in this area is Algorithmic Transparency. Machine learning (and other) algorithms for large-scale data analysis are routinely used for tasks as diverse as online content recommendation (Facebook), targeted ads (AdWords, DoubleClick), allocation of labor (Uber), medical diagnosis, and prediction of criminal activity (Northpointe Analytics). However, the general public (including users, regulators) has little information on the data and algorithms used by these systems. Consequently, our focus is on mathematical models needed to evaluate mechanisms that address fairness, privacy, and utility in the context of Algorithmic Transparency Reports (ATRs) . We investigate and demonstrate potential privacy hazards brought on by the deployment of transparency and fairness measures in released ATRs. To preserve data subjects’ privacy, we then propose a linear-time optimal-privacy scheme and quantify the privacy-utility trade-offs induced by this scheme (Chen et al., 2022).
Our earlier work also focused on the optimality of noise generation mechanisms that take into consideration query sensitivity, query side information, and longitudinal/collusion attacks. In our work (Chen et al., 2016), we investigate oblivious noise generation mechanisms for scalar queries, in non-Bayesian and Bayesian user settings, and provide supporting evidence and counterexamples to existing theory results for relaxed assumption sets.
The proliferation of public cloud providers and advancements in virtualization technologies create new opportunities: end-users can integrate private datacenters with public clouds to save on costs while satisfying privacy requirements; federations of small-scale cloud providers can partner with each other, to create economies of scale and sustain workload spikes while retaining business autonomy; cloud brokers can take advantage of multiple spot markets and volume discounts to make profit. Our goal is to develop mathematical performance and market models to evaluate the economic opportunities of cloud markets. For example, in (Pal et al., 2013) we proposed models for cloud pricing and capacity planning; in (Song et al., 2013), we addressed mechanism design for datacenter spot markets. In (Song et al., 2022) we used Markov chains to model federations of hybrid clouds and their QoS requirements, quantifying the benefits of resource sharing.
With ever-growing data volumes generated and stored across geo-distributed locations, it is increasingly inefficient to aggregate all data required for computation at a single datacenter. Instead, one can distribute computation to take advantage of data locality, thus reducing the costs (e.g., bandwidth) while improving performance. This leads to challenges for job scheduling, which requires coordination among datacenters as each job runs across geo-distributed sites. We proposed novel job scheduling algorithms that coordinate across datacenters with low overhead and near-optimal performance (Hung et al., 2015). We also considered a key difference between geo-distributed and intra-cluster jobs, namely, the heterogeneous (and often constrained) nature of compute and network resources across the sites and proposed Tetrium, a system for multi-resource allocation in geo-distributed clusters, that jointly considers both compute and network resources for task placement and job scheduling. Tetrium significantly reduces job response time, while incorporating several other performance goals with simple control knobs (Hung et al., 2018). Our efforts in this area also consider a stochastic optimization approach for job scheduling and server management, where we developed a two-time-scale decision strategy that offers provable power cost and delay guarantees (Yao et al., 2012).
Inconsistent quality of service is a significant problem in P2P video streaming systems: playback pauses are common for low-capacity peers, as they can usually upload relatively little compared to high-capacity ones. In (Wang et al., 2014) we proposed a framework where high-capacity peers are rewarded with reduced ads duration; a system for P2P video streaming based on this framework was analyzed in (Lin et al., 2015). Our approach adopts utility-theoretic market models, where market stakeholders consist of a content provider, an advertisement provider, and network peers. Using game theory, we determined optimal system parameters to reach market efficiency, and studied the practical implications of equilibria on stakeholders' satisfaction.
Cyber-insurance protects businesses and individuals from risks due to attacks to IT infrastructure (e.g., data destruction, extortion, theft, hacking, and denial of service), reducing liability for damages caused to others by errors or omissions. In (Pal et al., 2010), we proposed a general mathematical framework by which cooperative and non-cooperative Internet users can decide whether or not to invest in self-defense mechanisms (e.g., personal antivirus) when insurance plans are offered. In (Pal et al., 2014), we proved the inefficiency of cyber-insurance markets under conditions of partial information, asymmetry and correlated risks, and showed the existence of efficient markets (both regulated and unregulated) under premium discrimination.
Requirements of modern software systems dictate an early assessment of dependability qualities (such as reliability) in their life cycle. In (Cheung et al., 2012), we proposed SHARP, an architecture-level reliability prediction framework that analyzes a hierarchical, scenario-based specification of system behavior. Models of basic scenarios are solved and combined to obtain results for higher-lever scenarios composed by sequential and parallel executions.